서론
DNA분석 기술의 발달과 단일염기다형성(Single nucleotide polymorphism, SNP) 칩의 분석비용이 감소되면서 젖소의 경제형질들에 대한 양적형질좌위(Quantitative trait locus, QTL) 및 Tagging SNPs에 대한 대한 발굴 연구는 꾸준히 이루어졌으나 주로 1차회귀식에 의한 유전체연관분석(Genome-wide association study, GWAS)이 주를 이루었다(Pryce et al., 2010; Jiang et al., 2010; Mai et al., 2010; Guo et al., 2012; Cho et. al., 2015).
VanRaden (2008)는 유전체 혈연계수행렬(Genomic relationship matrix, GRM)의 계산 알고리즘 및 유전체 육종가(Genomic expected breeding value, GEBV)를 추정하는 방법을 제시하였으며, Misztal 등(2009)은 기존 혈통정보와 유전체정보결합 알고리즘을 발표하였다. Liu 등(2014)은 SNP Single-step genomic model을 개발하여 분석모형에서 SNP 효과를 직접 추정 할 수 있는 방법을 제시하였으며, 이후 젖소의 유전체 선발 대한 많은 연구가 진행되었다(Winkelmal et al., 2015; Garcia-Ruiz et al., 2016; Jattawa et al., 2016; Nguyen et al., 2016). 따라서 본 연구의 목적은 국내 젖소집단의 산차별 유생산형질에 대한 SNPs의 효과를 추정하고 이들의 분포적 특성을 구명하는데 있다
재료 및 방법
유전체 자료
2013년부터 국내 보유 중인 동결정액 및 착유 중인 젖소에서 DNA시료를 채취한 후 BovineSNP50 BeedChip(Illumina, USA)을 이용하여 총 2,090두(씨수소: 507, 씨암소: 1,583)에 대한 50,908개의 SNP정보를 수집하였다.
유전체자료의 품질평가는 성염색체상에 존재하는 SNP(1,139개)와 염색체상의 위치정보가 확인되지 않은 SNP(536개)를 제거하고 총 49,233개의 SNP를 이용하여 품질평가를 실시하였다. 품질평가에서 각 SNP별 결측률이 10% 이상, 다형성이 없는 SNP(모두 동형이거나 이형인 경우), 소수대립유전자빈도가 1% 이하인 경우와 하디-와인버그평형(Hardy-Weinberg equilibrium) 검사에서 χ2 < 23.93 이상인 SNP(7,396개)는 삭제하였다. 또한 SNP의 결측률이 10% 이상인 개체들(83두)은 분석에서 제외하였으며, 품질평가 후 결측된 SNP 유전형은 Beagle genetic analysis software를 이용하여 결측값을 대체하였으며, 실제로 분석에 이용된 개체와 SNP의 수는 각각 2,007두와 41,837개였다
표현형 자료
농협중앙회 젖소개량사업소와 한국종축개량협회로부터 2002년 1월부터 2016년 12월 사이에 분만한 홀스타인 젖소 736,402두의 유생산형질에 대한 검정자료, 총 1,754,714개를 수집하였다. 원자료에서는 305일 누적 유량의 기록이 2,500kg 미만이거나 16,000kg 초과인 경우, 305일 누적 유지방량의 기록인 70kg 미만이거나 600kg 초과인 경우, 305일 누적 유단백량기록이 80kg 미만이거나 500kg초과인 경우와 분만산차 기록이 누락되거나 3산을 초과한 경우 검정자료는 제외되었다
또한 검정단위(목장-분만년도-계절)내 기록의 수가 5개 미만인 자료와 산차별 분만월령이 1산차(17~31개월), 2산차(31~45개월), 3산차(45~59개월)의 범위를 벗어나는 자료 및 1산차의 검정기록이 있는 개체들 중에서 검정단위(목장- 분만년도-계절) 내 기록 수가 5개 이하의 자료는 제외되었다. 따라서 실제로 분석에 이용된 자료는 젖소 293,855두의 유생산기록, 총 506,481개였으며, 자료의 분포 및 특성은 Table 1에 제시하였다.
통계적 방법
분석모형은 다산차 다형질(Multiple lactation model)을 이용하였고(Jamrozik et al., 2007), 고정효과에는 검정단위(목장-분만연도-분만계절)과 분만월령을 포함하였으며, 유량, 유지방량과 유단백량의 산차별 검정기록은 각각의 형질로 간주되었다. 따라서 산차별 유량, 유지방량과 유단백량에 대한 (공)분산성분과 유전체육종가는 유량, 유지방량과 유단백량별로 추정하였으며, 분석에 이용된 통계적 모형은 다음과 같다.
|
Table 1. No. of records (percentage), means and standard deviations for 305-days milk, fat and protein yields (kg) by parity 
|
yi = Xibi + Ziai + ei
위에서, yi = i번째 산차의 검정기록, bi =i번째 산차의 검정기록에 대한 고정효과, ai = i번째 산차의 검정기록에 대한 개체의 상가적 유전효과, ei = i번째 산차의 검정기록에 대한 임의오차효과, Xi , Zi = i번째 산차의 검정기록과 관련된 빈도행렬이며, 산차간 대응관측치가 없기 때문에 오차 분산-공분산행렬에서 공분산값은 0가 된다.
위에서, yi = i번째 산차의 검정기록, bi =i번째 산차의 검정기록에 대한 고정효과, ai = i번째 산차의 검정기록에 대한 개체의 상가적 유전효과, ei = i번째 산차의 검정기록에 대한 임의오차효과, Xi , Zi = i번째 산차의 검정기록과 관련된 빈도행렬이며, 산차간 대응관측치가 없기 때문에 오차 분산-공분산행렬에서 공분산값은 0가 된다
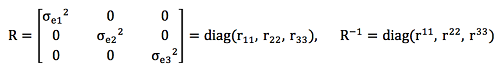
따라서 혼합모형방적식 (Mixed model equation, MME)은 다음과 같다.
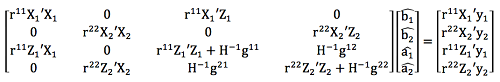
위에서, g11, g22= 유전분산, g12, g21=유전공분산, r11, r22= 오차분산, r12, r21=오차공분산,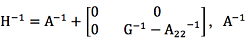 혈연계수행렬의 역행렬, G − 1= 유전체관계행렬의 역행렬, A22 − 1=유전체정보가 있는 개체들에 대한 혈연계수행렬의 역행렬이다. 각 SNP 표지인자별 효과는 아래와 같이 GEBV의 역 연산방식을 통하여 추정할 수 있다.
혈연계수행렬의 역행렬, G − 1= 유전체관계행렬의 역행렬, A22 − 1=유전체정보가 있는 개체들에 대한 혈연계수행렬의 역행렬이다. 각 SNP 표지인자별 효과는 아래와 같이 GEBV의 역 연산방식을 통하여 추정할 수 있다.
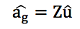
위에서, a^g는 유전체 육종가 벡터, Z는 SNP의 계수행렬, û는 SNP 효과벡터이다. 이를 분산의 식으로 변환하면 아래와 같다
G* = ZDZ′λ
위에서, D는 가중치 벡터이다. 위의 두 개 수식을 이용하여 아래와 같이 SNP효과에 대한 수식으로 변환할 수 있다.
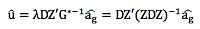
위에서, û= SNP 효과 벡터, $\widehat{a_{g}}$= 유전체 육종가 벡터, , Z= SNP와 관련된 계수행렬, D=가중치 벡터이다 (Wang et. al., 2014).
형질별 분산-공분산성분과 유전체 육종가는 Window 7 Ultimate K 운영체계의 Intel(R) CPU E5-2609 v3 @ 1.90GHz (2 processor, 128GB RAM) 컴퓨터를 이용하여 BLUPF90 family 프로그램(Misztal et. al, 2015)으로 추정하였다.
결과 및 고찰
환경효과
1) 검정단위 (목장-분만년도-계절
총 506,481개의 분석자료 내 목장의 수는 4,479개였으며, 목장별 평균 113개의 검정자료가 생성되었다. 분만 계절효과는 봄(3~5월), 여름(6월~8월), 가을(9월~11월), 겨울(12월~2월) 등 사계절로 구분하였고 목장-분만년도-계절의 수는 총 62,287개였으며, 검정단위의 평균 크기는 8.1개였다. 유생산형질에 영향을 미치는 목장-분만년도-계절 효과의 크기를 추정하기 위하여 Nested procedure(SAS 9.3)을 수행하였다.
유생산형질에 대한 목장의 효과는 전체 변이에 대하여 유량, 유지방량과 유단백량에서 각각 19.8%, 24.9%와 22.2%로 다른 효과들에 비하여 가장 크게 나타났으며, 분만연도의 효과는 11.2~13.8%의 범위를 나타내었다. 분만계절의 효과는 가장 작았으며, 4.3~4.4%의 범위를 나타내었다(Table 1). 유생산형질에 대한 검정단위의 효과는 전체 변이의 35.3~40.3%를 설명할 수 있는 가장 중요한 환경효과이다.
2) 분만월령
유량, 유지방량, 유단백량에 대한 분만월령의 1차와 2차 회귀계수는 모두 유의차 (P < 0.01)가 인정되었으며, 결정계수의 범위는 0.97~0.98이었다(Table 2).
유전모수
1산차의 유량, 유지방량과 유단백량에 대한 유전력은 각각 0.28, 0.26과 0.23으로 추정되었으며, 산차가 증가할수록 유전력은 감소하였으며(Table 3), 이러한 경향은 외국의 보고와 일치하였다(Powell과 Norman, 1981; Montaldo 등, 2010).
산차가 증가할수록 유전력이 감소하는 원인은 산차가 증가할수록 유전요인보다는 환경적 요인이 유생산형질에 더 많이 작용하기 때문이며, 유지방량이 유량과 유단백량에 비하여 2차산 이후부터 환경의 영향을 덜 받는 것으로 나타났다. 유량, 유지방량, 유단백량에서 산차간 유전상관계수의 범위는 0.85 ~ 0.99로 매우 높게 나타났으며, 표현형상관계수의 범위는 0.42 ~ 0.52로 유전상관계수보다 항상 낮게 나타났다. 이러한 결과는 외국의 보고와 일치하였다. 인터불 (2017)자료에 따르면 스페인 (유량 0.28, 유지방량 0.28, 유단백량 0.28), 독일(유량 0.37, 유지방량 0.36, 유단백량 0.35), 캐나다(유량 0.43, 유지방량 0.34, 유단백량 0.40), 체코(유량 0.39, 유지방량 0.38, 유단백량 0.37), 스위스(유량 0.55, 유지방량 0.47, 유단백량 0.51), 남아프리카공화국 (유량 0.18, 유지방량 0.11, 유단백량 0.14)으로 보고되었다.
|
Table 1. Percentages of the total variance in milk production traits (kg) accounted for by herd, year, season and error
|
|
Table 2. Linear and quadratic regression coefficients of month of age at calving for milk production traits (kg) 
|
|
**P < 0.01. |
|
Table 3. Heritabilities, standard errors, genetic and phenotypic correlations among parity in each trait 
|
|
Diagonal: heritability, upper triangle: phenotypic, lower triangle: genetic correlation |
Genome-wide association study (GWAS)
1) SNP 효과의 분포
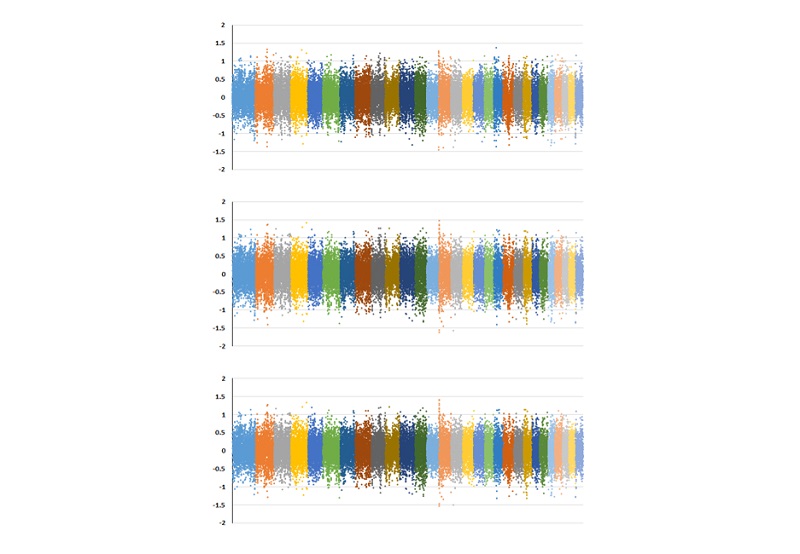
BLUPF90 family 프로그램(Misztal et. al, 2015)의 ssBLUP(Single step best linear unbiased prediction)은 유전체 정보를 가진 개체의 표현형과 혈통정보만을 가지는 개체 모두의 표현형을 이용할 수 있기 때문에 한번의 분석을 통하여 기존 육종가(EBV)와 유전체 육종가(GEBV)를 동시에 추정해 낼 수 있으며, 역 연산방법을 통하여 SNPs 효과를 추정할 수 있다(Wang et. al., 2014), 산차별 유량, 유지방량과 유단백량에 대한 SNP(41,837개) 효과의 추정치 값은 각각 –1.61~1.48kg, -0.07~0.07kg과 –0.04~0.04kg의 범위를 나타내었으며, 1산차 유량에 대하여 추정된 SNPs 효과 값의 분포를 염색체별로 구분하여 Figure 2에 나타내었다.
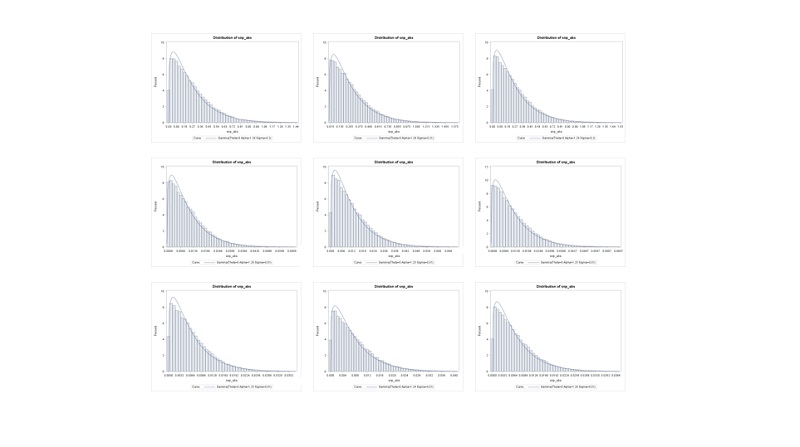
또한 추정된 SNP 효과 값은 절대 값으로 변환한 후 감마분포의 모수 값을 이용하여 산차별 유량, 유지방량과 유단백량에 대한 SNP 효과 값의 크기별 분포를 제시하였다(Figure 3). 대부분의 SNPs 효과 값은 유량(0~1kg), 유지방량(0~0.5kg)과 유단백량(0~0.3kg)에서 매우 작은 값들이 대부분 분포하고 있었으며, 상대적으로 크기가 큰 SNPs는 소수만 존재하는 것을 확인할 수 있었다.
2) SNP 효과의 표준화
유량, 유지방량과 유단백량에 대하여 추정된 SNP 효과 값의 상대적 크기를 비교하기 위하여 SNP 효과 값을 표준화시킨 후 다시 절대 값을 취하였다(Figure 4). 정규분포에서 3×표준편차의 범위 내에서 SNP 추정치의 약 99.74%가 분포한다고 가정하고, 유용 유전자로서의 선별 기준점은 4×표준편차 이상으로 하였다.
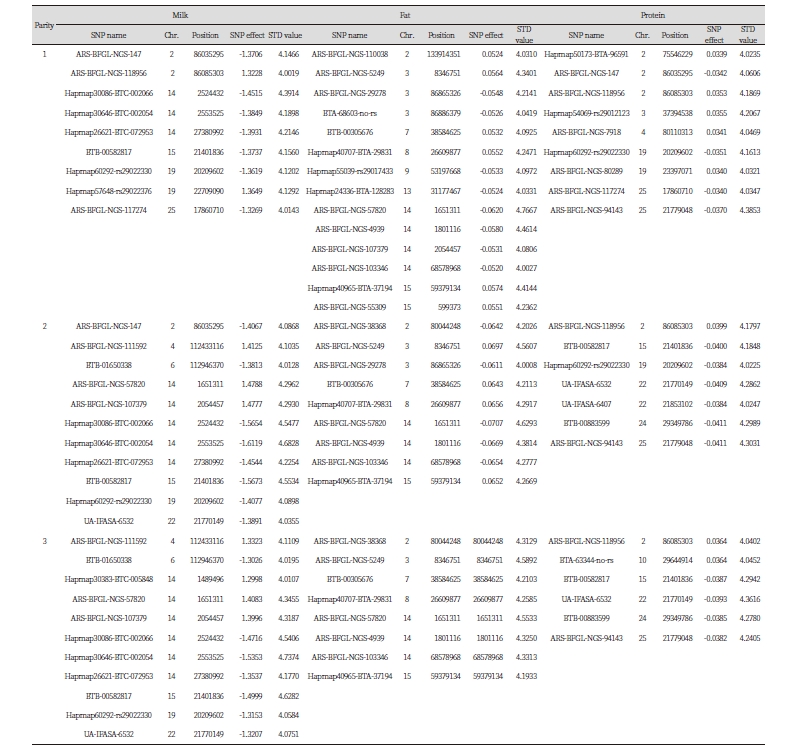
유량에 대한 4×표준편차 이상의 값을 지닌 SNP의 수는 1산, 2산과 3산에서 각각 9개, 11개와 11개였다. 모든 산차에서 공통으로 4이상의 값을 나타낸 SNP의 수는 5개로 14번 염색체 3개(Hapmap30086-BTC-002066, Hapmap30646-BTC-002054, Hapmap26621-BTC-072953), 15번 염색체 1개(BTB-00582817), 19번 염색체 1개(Hapmap60292-rs29022330)였다 (Table 4).
유지방량에 대한 4×표준편차의 값을 지닌 SNP의 수는 1산, 2산, 3산에서 각각 14개, 9개와 8개였다. 모든 산차에서 공통으로 4이상의 값을 나타낸 SNP의 수는 8개로 2번 염색체 1개(ARS-BFGL-NGS-38368), 3번 염색체 1개(ARS-BFGL-NGS-5249), 7번 염색체 1개(BTB-00305676), 8번 염색체 1개(Hapmap40707-BTA-29831), 14번 염색체 3개(ARS-BFGL-NGS-57820, ARS-BFGL-NGS-4939, ARS-BFGL-NGS-103346), 15번 염색체 1개(Hapmap40965-BTA-37194) 였다 (Table 4).
유단백량에 대한 4×표준편차의 값을 지닌 SNP의 수는 1산, 2산과 3산에서 각각 9개, 7개와 6개였다. 모든 산차에서 공통으로 4이상의 값을 나타낸 SNP의 수는 2개로 2번 염색체 1개(ARS-BFGL-NGS-118956)와 25번 염색체 1개(ARS-BFGL-NGS-94143)로 나타났다(Table 4).
|
|
|
Figure 3. Distribution of the estimated SNP effects for milk, fat and protein yields (from top to low) (kg) by parity (1~3) (from left to right). |